Python 中的 Fama-Macbeth 回归
本篇文章介绍了 Fama-Macbeth 回归、其重要性及其实施。
Fama-Macbeth 回归及其重要性
在资产定价理论中,我们使用风险因素来描述资产收益。 这些风险因素可以是微观经济或宏观经济。
微观经济风险因素包括公司规模和公司不同的财务指标,而宏观经济风险因素是消费者通胀和失业率。
Fama-Macbeth 回归是用于测试资产定价模型的两步回归模型。 这是衡量这些风险因素描述投资组合或资产回报的正确程度的实用方法。
该模型可用于确定与暴露于这些因素相关的风险溢价。
现在,关键是,为什么我们称 Fama-Macbeth 为两步回归模型? 让我们在下面找出这些步骤。
- 这一步是关于使用时间序列方法根据一个或多个风险因素对每项资产的回报进行回归。 我们获得了对每个因素的回报敞口,这些因素被称为贝塔系数、因素负荷或因素敞口。
- 这一步是关于使用横截面方法根据上一步(步骤 1)中获得的资产贝塔回归所有资产的回报。 在这里,我们得到每个因素的风险溢价。
根据 Fama 和 Macbeth 的说法,然后通过对每个元素平均一次系数来计算单位暴露于每个风险因素的随时间推移的预计溢价。
在 Python 中实现 Fama-Macbeth 回归的步骤
根据反映 2018 年秋季 Fama-Macbeth 图书馆情况的更新,fama_macbeth 已经从 Python pandas 模块中删除了一段时间。
那么,如果我们使用 Python,我们如何实现 Fama-Macbeth? 我们将在本教程中一一学习以下两种方法。
- 如果我们使用 Python 版本 3,我们可以在 LinearModels 中使用 fama_macbeth 函数。
- 如果我们不需要使用 LinearModels,或者我们正在使用 Python 版本 2,那么最好的情况很可能是为 Fama-Macbeth 编写我们的实现。
使用 LinearModels 在 Python 中实现 Fama-Macbeth 回归
-
导入必要的模块和库。
import pandas as pd import numpy as np from pathlib import Path from linearmodels.asset_pricing import LinearFactorModel from statsmodels.api import OLS, add_constant import matplotlib.pyplot as plt import pandas_datareader.data as web import seaborn as sns import warnings warnings.filterwarnings('ignore') sns.set_style('whitegrid')首先,我们导入使用 LinearModels 实现 Fama-Macbeth 所需的所有模块和库。 下面给出了所有这些的简要说明:
- 我们导入 pandas 来处理数据框,导入 numpy 来处理数组。
- pathlib 通过将此特定脚本放在 Path 对象中来创建指定文件的路径。
- 我们从 linearmodels.asset_pricing 导入 LinearFactorModel。 线性因子模型将资产回报与有限/有限数量的因子值相关联,其关系由线性方程描述。
- 接下来,我们导入 OLS 来评估线性回归模型,并导入 add_constant 以将一列 1 添加到数组中。 您可以在此处了解有关统计模型的更多信息。
- 之后,我们导入 pandas_datareader 以访问最新的远程数据以与 pandas 一起使用。 它适用于各种熊猫版本。
- 我们导入 matplotlib 和 seaborn 库用于数据绘图和可视化目的。
- 我们导入 Warnings 以使用其 filterwarnings() 方法,该方法会忽略警告。
- 最后,我们使用 seaborn 模块中的 set_style() 方法,它设置控制绘图一般样式的参数。
-
访问远程风险因素和研究组合数据集。
ff_research_data_five_factor = 'F-F_Research_Data_5_Factors_2x3' ff_factor_dataset = web.DataReader(ff_research_data_five_factor, 'famafrench', start='2010', end='2017-12')[0]在这里,我们使用他们网站上提供的更新的风险因素和研究组合数据集(五个 Fama-French 因素)返回到我们在 2010-2017 年获得的每月频率,如上所示。
我们使用
DataReader()从指定的互联网资源中提取数据到 pandas 数据框中,在我们的代码围栏中是 ff_factor_dataset。DataReader()支持各种来源,例如 Tiingo、IEX、Alpha Vantage 以及您可以在此页面上阅读的更多来源。print("OUTPUT for info(): \n") print(ff_factor_dataset.info())接下来,我们使用
df.info()和df.describe()方法,其中info()打印数据框的信息,包括列数、列的数据类型、列标签、范围索引、内存使用情况和数量 每列中的单元格(非空值)。您可以在下面看到 info() 产生的输出。
输出:
OUTPUT for info(): <class 'pandas.core.frame.DataFrame'> PeriodIndex: 96 entries, 2010-01 to 2017-12 Freq: M Data columns (total 6 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 Mkt-RF 96 non-null float64 1 SMB 96 non-null float64 2 HML 96 non-null float64 3 RMW 96 non-null float64 4 CMA 96 non-null float64 5 RF 96 non-null float64 dtypes: float64(6) memory usage: 5.2 KB None接下来,我们使用
describe()方法如下。print("OUTPUT for describe(): \n") print(ff_factor_dataset.describe())describe()方法显示数据框的统计摘要; 我们也可以将此方法用于 Python 系列。 此统计摘要包含均值、中位数、计数、标准差、列的百分位值和最小值-最大值。您可以在下面找到
describe()方法的输出。输出:
OUTPUT for describe(): Mkt-RF SMB HML RMW CMA RF count 96.000000 96.000000 96.000000 96.000000 96.000000 96.000000 mean 1.158438 0.060000 -0.049271 0.129896 0.047708 0.012604 std 3.580012 2.300292 2.202912 1.581930 1.413033 0.022583 min -7.890000 -4.580000 -4.700000 -3.880000 -3.240000 0.000000 25% -0.917500 -1.670000 -1.665000 -1.075000 -0.952500 0.000000 50% 1.235000 0.200000 -0.275000 0.210000 0.010000 0.000000 75% 3.197500 1.582500 1.205000 1.235000 0.930000 0.010000 max 11.350000 7.040000 8.190000 3.480000 3.690000 0.090000 -
访问 17 个行业投资组合并减去风险因素率。
ff_industry_portfolio = '17_Industry_Portfolios' ff_industry_portfolio_dataset = web.DataReader(ff_industry_portfolio, 'famafrench', start='2010', end='2017-12')[0] ff_industry_portfolio_dataset = ff_industry_portfolio_dataset .sub(ff_factor_dataset.RF, axis=0)在这里,我们使用
DataReader()按月访问 17 个行业投资组合或资产,并从DataReader()返回的数据框中减去无风险利率 (RF)。 为什么? 这是因为因子模型适用于超额收益。现在,我们将使用
info()方法获取有关链接数据框的信息。print(ff_industry_portfolio_dataset.info())输出:
<class 'pandas.core.frame.DataFrame'> PeriodIndex: 96 entries, 2010-01 to 2017-12 Freq: M Data columns (total 17 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 Food 96 non-null float64 1 Mines 96 non-null float64 2 Oil 96 non-null float64 3 Clths 96 non-null float64 4 Durbl 96 non-null float64 5 Chems 96 non-null float64 6 Cnsum 96 non-null float64 7 Cnstr 96 non-null float64 8 Steel 96 non-null float64 9 FabPr 96 non-null float64 10 Machn 96 non-null float64 11 Cars 96 non-null float64 12 Trans 96 non-null float64 13 Utils 96 non-null float64 14 Rtail 96 non-null float64 15 Finan 96 non-null float64 16 Other 96 non-null float64 dtypes: float64(17) memory usage: 13.5 KB None同样,我们使用
describe()方法描述这个数据框。print(ff_industry_portfolio_dataset.describe())输出:
Food Mines Oil Clths Durbl Chems \ count 96.000000 96.000000 96.000000 96.000000 96.000000 96.000000 mean 1.046771 0.202917 0.597187 1.395833 1.151458 1.305000 std 2.800555 7.904401 5.480938 5.024408 5.163951 5.594161 min -5.170000 -24.380000 -11.680000 -10.000000 -13.160000 -17.390000 25% -0.785000 -5.840000 -3.117500 -1.865000 -2.100000 -1.445000 50% 0.920000 -0.435000 0.985000 1.160000 1.225000 1.435000 75% 3.187500 5.727500 4.152500 3.857500 4.160000 4.442500 max 6.670000 21.940000 15.940000 17.190000 16.610000 18.370000 Cnsum Cnstr Steel FabPr Machn Cars \ count 96.000000 96.000000 96.000000 96.000000 96.000000 96.000000 mean 1.186979 1.735521 0.559167 1.350521 1.217708 1.279479 std 3.142989 5.243314 7.389679 4.694408 4.798098 5.719351 min -7.150000 -14.160000 -20.490000 -11.960000 -9.070000 -11.650000 25% -0.855000 -2.410000 -4.395000 -1.447500 -2.062500 -1.245000 50% 1.465000 2.175000 0.660000 1.485000 1.525000 0.635000 75% 3.302500 5.557500 4.212500 3.837500 4.580000 4.802500 max 8.260000 15.510000 21.350000 17.660000 14.750000 20.860000 Trans Utils Rtail Finan Other count 96.000000 96.000000 96.000000 96.000000 96.000000 mean 1.463750 0.896458 1.233958 1.248646 1.290938 std 4.143005 3.233107 3.512518 4.839150 3.697608 min -8.560000 -6.990000 -9.180000 -11.140000 -7.890000 25% -0.810000 -0.737500 -0.952500 -1.462500 -1.090000 50% 1.480000 1.240000 0.865000 1.910000 1.660000 75% 4.242500 2.965000 3.370000 4.100000 3.485000 max 12.980000 7.840000 12.440000 13.410000 10.770000 -
计算超额收益。
在开始计算超额收益之前,我们必须执行更多步骤。
data_store = Path('./data/assets.h5') wiki_prices_df = (pd.read_csv('./dataset/wiki_prices.csv', parse_dates=['date'], index_col=['date', 'ticker'], infer_datetime_format=True).sort_index()) us_equities_data_df = pd.read_csv('./dataset/us_equities_data.csv') with pd.HDFStore(data_store) as hdf_store: hdf_store.put('quandl/wiki/prices', wiki_prices_df) with pd.HDFStore(data_store) as hdf_store: hdf_store.put('us_equities/stocks', us_equities_data_df.set_index('ticker'))首先,我们在位于当前目录的数据文件夹中创建一个 assets.h5 文件。 接下来,我们使用 read_csv() 方法从同一目录读取数据集文件夹中的 wiki_prices.csv 和 us_equities_data.csv 文件。
之后,我们使用上面给出的 HDFStore() 以 HDF5 格式存储数据。
with pd.HDFStore('./data/assets.h5') as hdf_store: prices = hdf_store['/quandl/wiki/prices'].adj_close.unstack().loc['2010':'2017'] equities = hdf_store['/us_equities/stocks'].drop_duplicates() sectors = equities.filter(prices.columns, axis=0).sector.to_dict() prices = prices.filter(sectors.keys()).dropna(how='all', axis=1) returns_df = prices.resample('M').last().pct_change().mul(100).to_period('M') returns_df = returns.dropna(how='all').dropna(axis=1) print(returns_df.info())在上面的代码栅栏中,我们读取了我们刚刚存储在 assets.h5 文件中的
/quandl/wiki/prices & /us_equities/stocks并将它们保存在 prices 和 equities 变量中。然后,我们对价格和股票应用一些过滤器、重新采样并删除缺失值。 最后,我们使用info()方法打印一个数据框returns_df的信息; 你可以看到下面的输出。
输出:
<class 'pandas.core.frame.DataFrame'> PeriodIndex: 95 entries, 2010-02 to 2017-12 Freq: M Columns: 1986 entries, A to ZUMZ dtypes: float64(1986) memory usage: 1.4 MB None现在,执行以下代码来对齐数据。
ff_factor_dataset = ff_factor_dataset.loc[returns_df.index] ff_industry_portfolio_dataset = ff_industry_portfolio_dataset.loc[returns_df.index] print(ff_factor_dataset.describe())输出:
Mkt-RF SMB HML RMW CMA RF count 95.000000 95.000000 95.000000 95.000000 95.000000 95.000000 mean 1.206000 0.057053 -0.054316 0.144632 0.043368 0.012737 std 3.568382 2.312313 2.214041 1.583685 1.419886 0.022665 min -7.890000 -4.580000 -4.700000 -3.880000 -3.240000 0.000000 25% -0.565000 -1.680000 -1.670000 -0.880000 -0.965000 0.000000 50% 1.290000 0.160000 -0.310000 0.270000 0.010000 0.000000 75% 3.265000 1.605000 1.220000 1.240000 0.940000 0.010000 max 11.350000 7.040000 8.190000 3.480000 3.690000 0.090000现在,我们准备好计算超额收益。
excess_returns_df = returns_df.sub(ff_factor_dataset.RF, axis=0) excess_returns_df = excess_returns_df.clip(lower=np.percentile(excess_returns_df, 1), upper=np.percentile(excess_returns_df, 99)) excess_returns_df.info()在上面的代码块中,我们从 ff_factor_dataset 中减去风险因子,并将返回的数据帧保存在 excess_returns_df 中。
接下来,我们使用 .clip() 方法修剪指定输入阈值处的值。 最后,使用 info() 打印 excess_returns_df 数据框的信息。
输出:
<class 'pandas.core.frame.DataFrame'> PeriodIndex: 95 entries, 2010-02 to 2017-12 Freq: M Columns: 1986 entries, A to ZUMZ dtypes: float64(1986) memory usage: 1.4 MB在进入 Fama-Macbeth 回归的第一阶段之前,我们使用
.drop()方法,它从列或行中删除指定的标签。 请注意,axis=1 表示从列中删除,axis=0 表示从行中删除。ff_factor_dataset = ff_factor_dataset.drop('RF', axis=1) print(ff_factor_dataset.info())输出:
<class 'pandas.core.frame.DataFrame'> PeriodIndex: 95 entries, 2010-02 to 2017-12 Freq: M Data columns (total 5 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 Mkt-RF 95 non-null float64 1 SMB 95 non-null float64 2 HML 95 non-null float64 3 RMW 95 non-null float64 4 CMA 95 non-null float64 dtypes: float64(5) memory usage: 4.5 KB None -
实施 Fama-Macbeth 回归步骤 1:因子暴露。
betas = [] for industry in ff_industry_portfolio_dataset: step_one = OLS(endog=ff_industry_portfolio_dataset .loc[ff_factor_dataset.index, industry], exog=add_constant(ff_factor_dataset)).fit() betas.append(step_one.params.drop('const')) betas = pd.DataFrame(betas, columns=ff_factor_dataset.columns, index=ff_industry_portfolio_dataset.columns) print(betas.info())上面的代码片段实现了 Fama-Macbeth 回归的第一步,并访问了 17 因子加载估计。 在这里,我们使用
OLS()来评估线性回归模型,并使用add_constant()将一列 1 添加到数组中。输出:
<class 'pandas.core.frame.DataFrame'> Index: 17 entries, Food to Other Data columns (total 5 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 Mkt-RF 17 non-null float64 1 SMB 17 non-null float64 2 HML 17 non-null float64 3 RMW 17 non-null float64 4 CMA 17 non-null float64 dtypes: float64(5) memory usage: 1.3+ KB None -
实施 Fama-Macbeth 回归步骤 2:风险溢价。
lambdas = [] for period in ff_industry_portfolio_dataset.index: step_two = OLS(endog=ff_industry_portfolio_dataset.loc[period, betas.index], exog=betas).fit() lambdas.append(step_two.params) lambdas = pd.DataFrame(lambdas, index=ff_industry_portfolio_dataset.index, columns=betas.columns.tolist()) print(lambdas.info())在第二步中,我们对投资组合横截面的因子负载进行了 96 次周期回报回归。
输出:
<class 'pandas.core.frame.DataFrame'> PeriodIndex: 95 entries, 2010-02 to 2017-12 Freq: M Data columns (total 5 columns): # Column Non-Null Count Dtype \--- ------ -------------- ----- 0 Mkt-RF 95 non-null float64 1 SMB 95 non-null float64 2 HML 95 non-null float64 3 RMW 95 non-null float64 4 CMA 95 non-null float64 dtypes: float64(5) memory usage: 6.5 KB None我们可以将结果可视化如下:
window = 24 # here 24 is the number of months axis1 = plt.subplot2grid((1, 3), (0, 0)) axis2 = plt.subplot2grid((1, 3), (0, 1), colspan=2) lambdas.mean().sort_values().plot.barh(ax=axis1) lambdas.rolling(window).mean().dropna().plot(lw=1, figsize=(14, 5), sharey=True, ax=axis2) sns.despine() plt.tight_layout()输出:
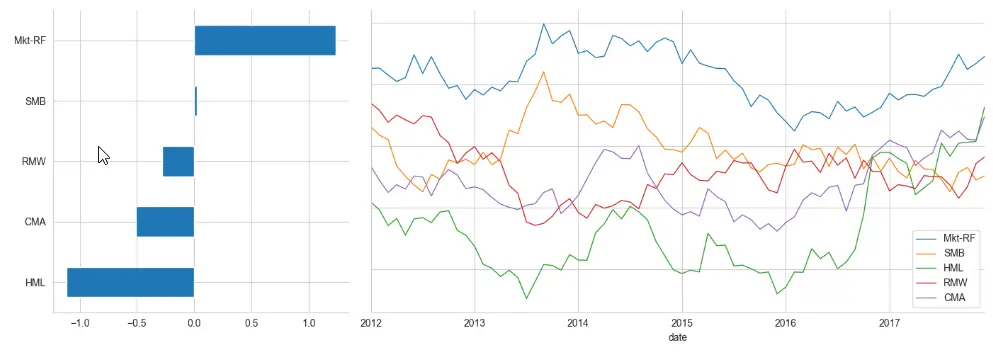
-
使用 LinearModels 模块实施 Fama-Macbeth 回归。
model = LinearFactorModel(portfolios=ff_industry_portfolio_dataset, factors=ff_factor_dataset) result = model.fit() print(result)在这里,我们使用 LinearModels 来实现产生以下输出的两步 Fama-Macbeth 过程。 我们可以使用
print(result.full_summary)而不是print(result)来获取完整的摘要。输出:
LinearFactorModel Estimation Summary ================================================================================ No. Test Portfolios: 17 R-squared: 0.6879 No. Factors: 5 J-statistic: 15.619 No. Observations: 95 P-value 0.2093 Date: Mon, Oct 24 2022 Distribution: chi2(12) Time: 20:53:52 Cov. Estimator: robust Risk Premia Estimates ============================================================================== Parameter Std. Err. T-stat P-value Lower CI Upper CI ------------------------------------------------------------------------------ Mkt-RF 1.2355 0.4098 3.0152 0.0026 0.4324 2.0386 SMB 0.0214 0.8687 0.0246 0.9804 -1.6813 1.7240 HML -1.1140 0.6213 -1.7931 0.0730 -2.3317 0.1037 RMW -0.2768 0.8133 -0.3403 0.7336 -1.8708 1.3172 CMA -0.5078 0.5666 -0.8962 0.3701 -1.6183 0.6027 ============================================================================== Covariance estimator: HeteroskedasticCovariance See full_summary for complete results
在 Python 中实现 Fama-Macbeth 回归的替代方法
如果我们不想使用 LinearModels 或使用 Python 版本 2,我们可以使用这种方法。
-
导入模块和库。
import pandas as pd import numpy as np import statsmodels.formula.api as sm -
读取和查询数据集。
假设我们在面板中有 Fama-French 行业资产/投资组合,如下所示(我们还计算了一些变量,例如,过去的 beta 和回报用作我们的 x 变量)
data_df = pd.read_csv('industry_data.csv',parse_dates=['caldt']) data_df.query("caldt == '1995-07-01'")industry caldt ret beta r12to2 r36to13 18432 Aero 1995-07-01 6.26 0.9696 0.2755 0.3466 18433 Agric 1995-07-01 3.37 1.0412 0.1260 0.0581 18434 Autos 1995-07-01 2.42 1.0274 0.0293 0.2902 18435 Banks 1995-07-01 4.82 1.4985 0.1659 0.2951 -
使用 groupby() 逐月计算横截面回归模型。
def ols_coefficient(x,formula): return sm.ols(formula,data=x).fit().params gamma_df = (data_df.groupby('caldt') .apply(ols_coefficient,'ret ~ 1 + beta + r12to2 + r36to13')) gamma_df.head()输出:
Intercept beta r12to2 r36to13 caldt 1963-07-01 -1.497012 -0.765721 4.379128 -1.918083 1963-08-01 11.144169 -6.506291 5.961584 -2.598048 1963-09-01 -2.330966 -0.741550 10.508617 -4.377293 1963-10-01 0.441941 1.127567 5.478114 -2.057173 1963-11-01 3.380485 -4.792643 3.660940 -1.210426 -
计算均值和均值的标准误差。
def fm_summary(p): s = p.describe().T s['std_error'] = s['std']/np.sqrt(s['count']) s['tstat'] = s['mean']/s['std_error'] return s[['mean','std_error','tstat']] fm_summary(gamma_df)输出:
mean std_error tstat Intercept 0.754904 0.177291 4.258000 beta -0.012176 0.202629 -0.060092 r12to2 1.794548 0.356069 5.039896 r36to13 0.237873 0.186680 1.274230 -
提高速度并使用 fama_macbeth 函数。
def ols_np(dataset,y_var,x_var): gamma_df,_,_,_ = np.linalg.lstsq(dataset[x_var],dataset[y_var],rcond=None) return pd.Series(gamma_df)要执行 ols 估计,我们可以编写一个类似于上述的函数。 请注意,我们没有做任何事情来检查这些矩阵的等级。
如果您使用的是较旧的 pandas 版本,则以下内容应该有效。 让我们举个例子,在 pandas 中使用 fama_macbeth。
print(data_df) fm = pd.fama_macbeth(y=data_df['y'],x=data_df[['x']]) print(fm)输出:
y x date id 2012-01-01 1 0.1 0.4 2 0.3 0.6 3 0.4 0.2 4 0.0 1.2 2012-02-01 1 0.2 0.7 2 0.4 0.5 3 0.2 0.1 4 0.1 0.0 2012-03-01 1 0.4 0.8 2 0.6 0.1 3 0.7 0.6 4 0.4 -0.1 ----------------------Summary of the Fama-Macbeth Analysis------------------------- Formula: Y ~ x + intercept # betas : 3 ----------------------Summary of the Estimated Coefficients------------------------ Variable Beta Std Err t-stat CI 2.5% CI 97.5% (x) -0.0227 0.1276 -0.18 -0.2728 0.2273 (intercept) 0.3531 0.0842 4.19 0.1881 0.5181 --------------------------------End of the Summary---------------------------------如果我们不想拦截,我们可以这样做。
fm = pd.fama_macbeth(y=data_df['y'],x=data_df[['x']],intercept=False)
相关文章
Pandas DataFrame DataFrame.shift() 函数
发布时间:2024/04/24 浏览次数:133 分类:Python
-
DataFrame.shift() 函数是将 DataFrame 的索引按指定的周期数进行移位。
Python pandas.pivot_table() 函数
发布时间:2024/04/24 浏览次数:82 分类:Python
-
Python Pandas pivot_table()函数通过对数据进行汇总,避免了数据的重复。
Pandas read_csv()函数
发布时间:2024/04/24 浏览次数:254 分类:Python
-
Pandas read_csv()函数将指定的逗号分隔值(csv)文件读取到 DataFrame 中。
Pandas 多列合并
发布时间:2024/04/24 浏览次数:628 分类:Python
-
本教程介绍了如何在 Pandas 中使用 DataFrame.merge()方法合并两个 DataFrames。
Pandas loc vs iloc
发布时间:2024/04/24 浏览次数:837 分类:Python
-
本教程介绍了如何使用 Python 中的 loc 和 iloc 从 Pandas DataFrame 中过滤数据。
在 Python 中将 Pandas 系列的日期时间转换为字符串
发布时间:2024/04/24 浏览次数:894 分类:Python
-
了解如何在 Python 中将 Pandas 系列日期时间转换为字符串

